Data Lake
Là repository chứa structured và unstructured data, không cần khởi tạo structure ban đầu, có thể scale, tạo dashboard, visualization, big data process, realtime analytic, machine learning đối với data lake.
OpenSearch (ElasticSearch)
- Search theo field, hoặc 1 phần của field
- Thường sử dụng để làm phần bổ sung cho DB khác
- Managed Cluster
- Serverless Cluster
- Không hỗ trợ trực tiếp SQL nhưng có thể cài qua plugin
- Data source có thể từ Kinesis Data FireHose, IoT, CloudWatch Logs hoặc custom Application
- Security cùng Cognito, IAM, KMS, TLS
- Có thể tạo Dashboard
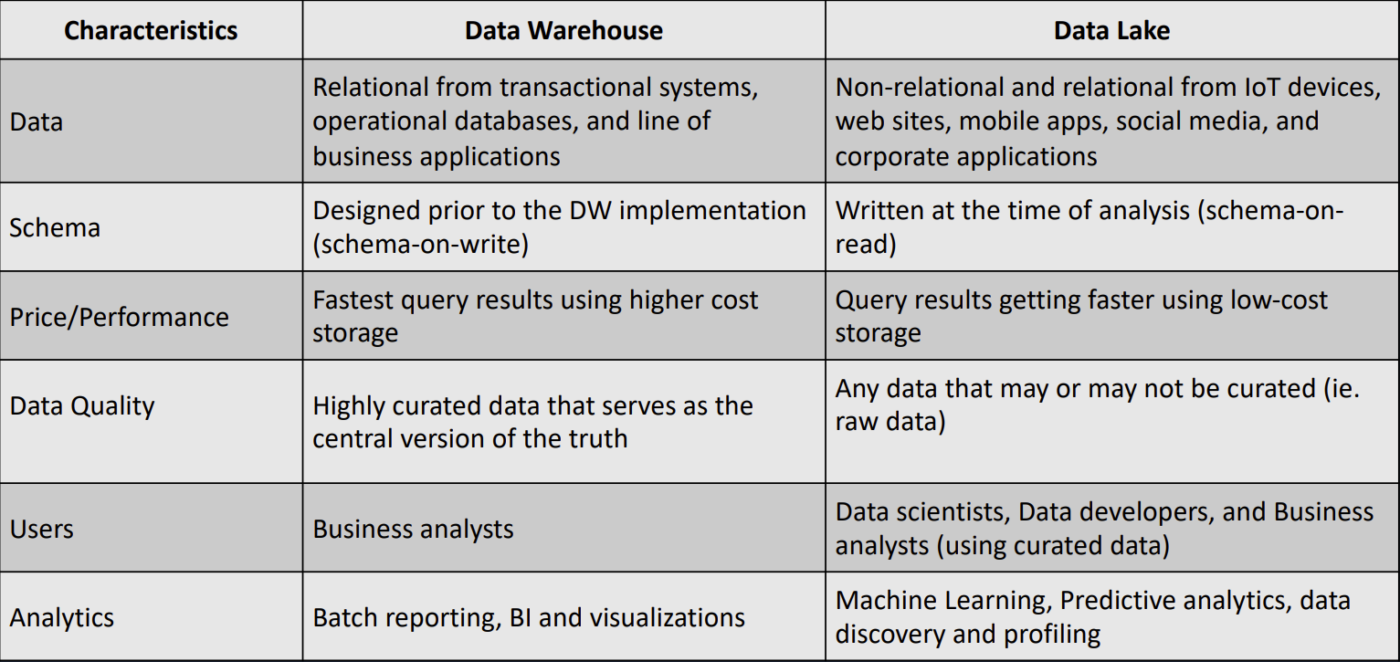
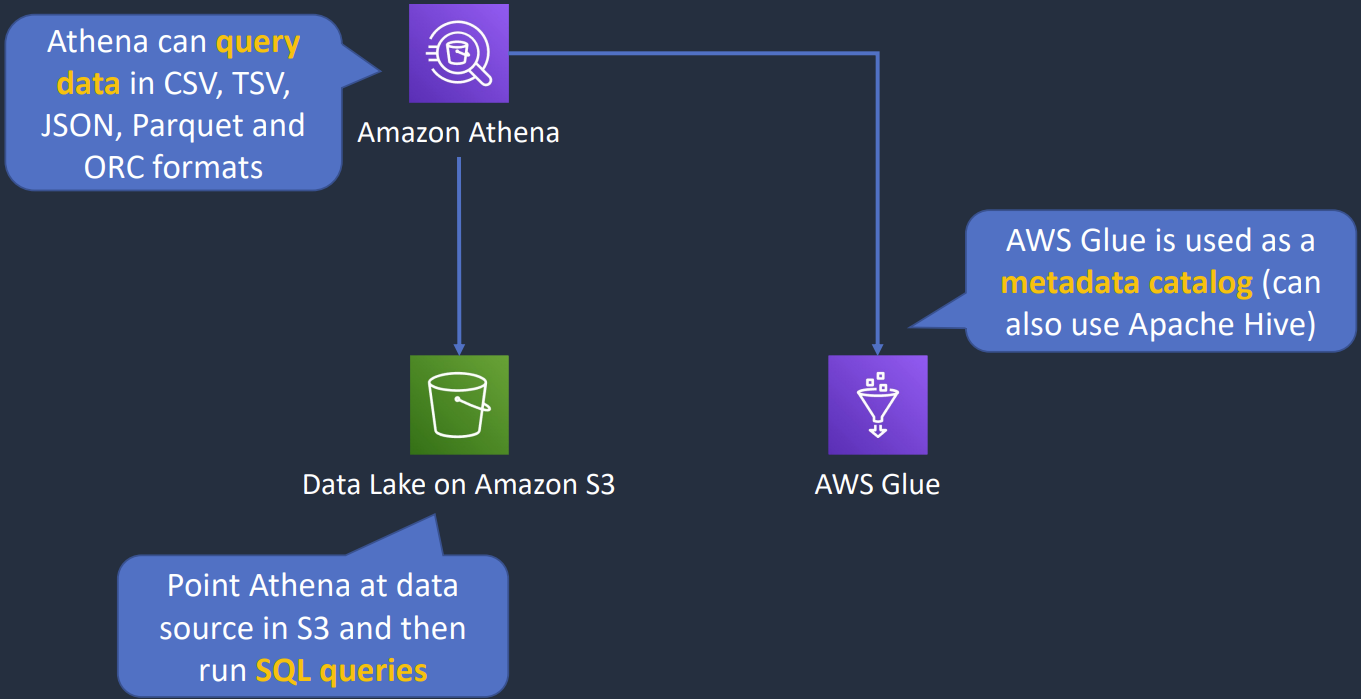
AWS Glue
Là ETL service (Extract, Transform, Load), sử dụng để chuẩn bị data query, run job bằng Apache Spark, lấy ra và lưu metadata (table definetion & schema) bằng AWS Glue Data Catalog.
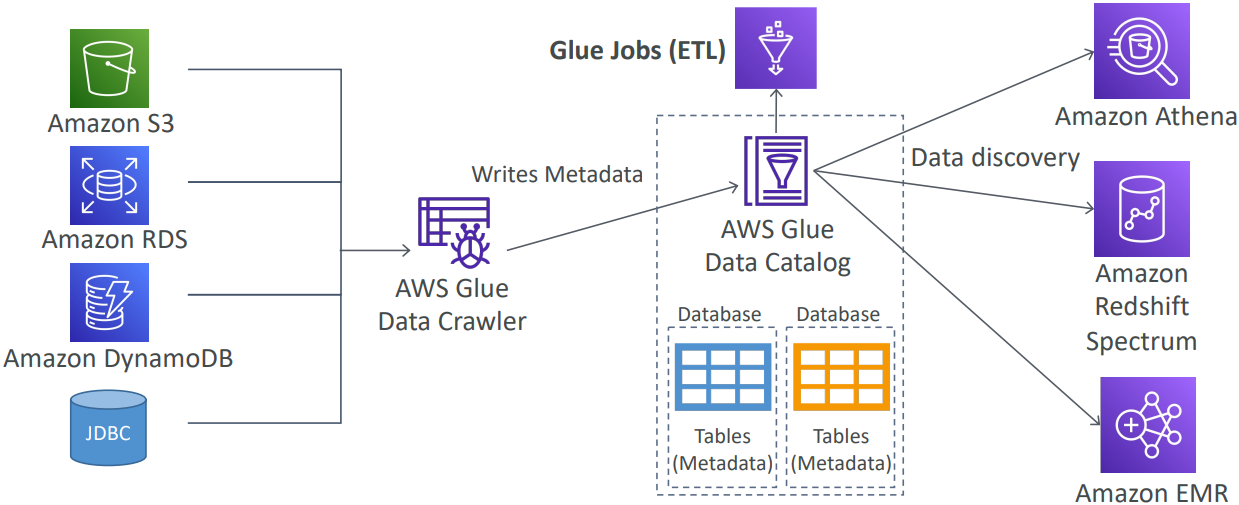
- Hoạt động với data lake (như S3), data warehouse (như Redshift) hoặc data store (RDS hoặc EC2 Database)
- Có thể convert data sang Parquet (fornat tốt hơn cho Athena)
- Job Bookmark: Ngăn xử lý lại data cũ
- Elastic View:
- Sử dụng SQL để kết hợp và replicate data giữa các data store
- Không cần custom code
- “Virtual table”
- Data Brew: clean và normalize data sử dụng pre-built transformation
- Studito: GUI mới của Glue, sử dụng để tạo và run Job
- Streaming ETL: Tương thích với
- Data Catalog: Chứa metadata của các source database
- Crawler: Sử dụng để đổ data vào AWS Glue Data Catalog bằng table
- Có thể crawl multiple data strore trong 1 lần chạy, sau khi chạy xong sẽ create/update table trong Data Catalog
- ETL Job define trong AWS Glue sẽ dùng Data Catalog table làm source/target
Amazon Athena
Là serverless service dùng để run SQL query để lấy thông tin từ datasourrce, thường là từ S3, nhưng cũng có thể từ CloudWatch Logs, CloudWatch Metrics, MySQL, DynamoDB, DocumentDB, Apache HBase… Một vài trường hợp cần Lambda function để connect Athena với Datasource để map data với table trong Athena.
- Support CSV, JSOP, ORC, Avro, Parquet
- 5$ cho 1TB data scan
- Thường sử dụng cùng Quicksight để làm report/dashboard
Optimizing Performance Athena
- Recommend sử dụng Apache Parquet or ORC
- Sử dụng Glue để convert data sang Parquet or ORC
- Compression: bzip2, gzip, lz4, snappy, zlip, zstd…)
- Lưu object đúng folder mà có thể query theo key -> không cần đọc data từ object
- Sử dụng file lớn, nhiều file nhỏ sẽ làm chậm performance
- Optimize ORDER BY và GROUP BY
- Sử dụng các function gần đúng
- Chỉ lấy ra các column cần sử dụng
Xem thêm tại đây: https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
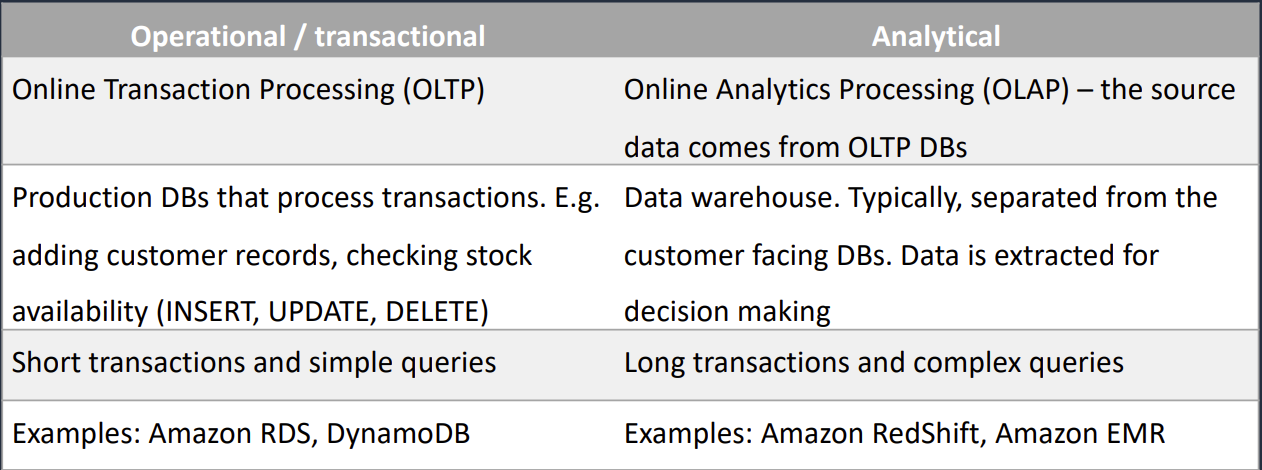
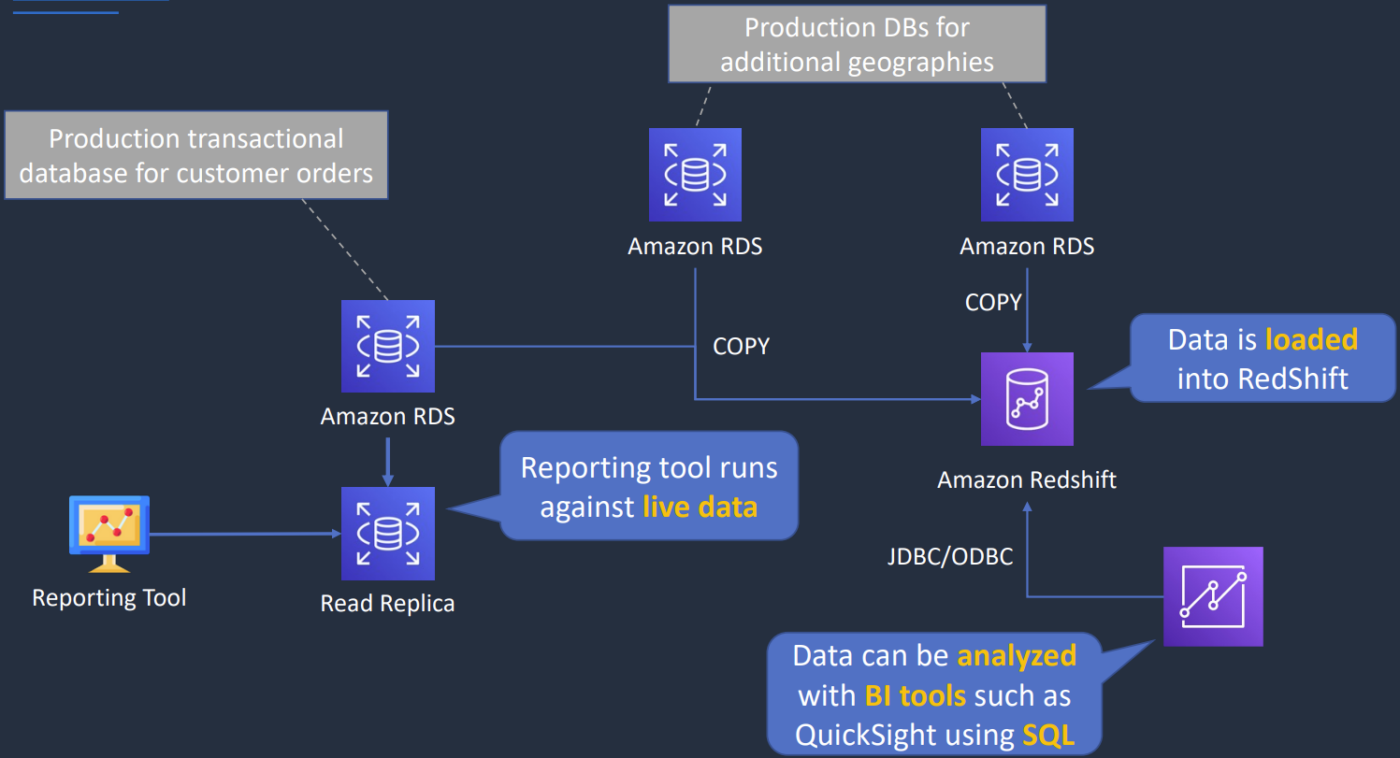
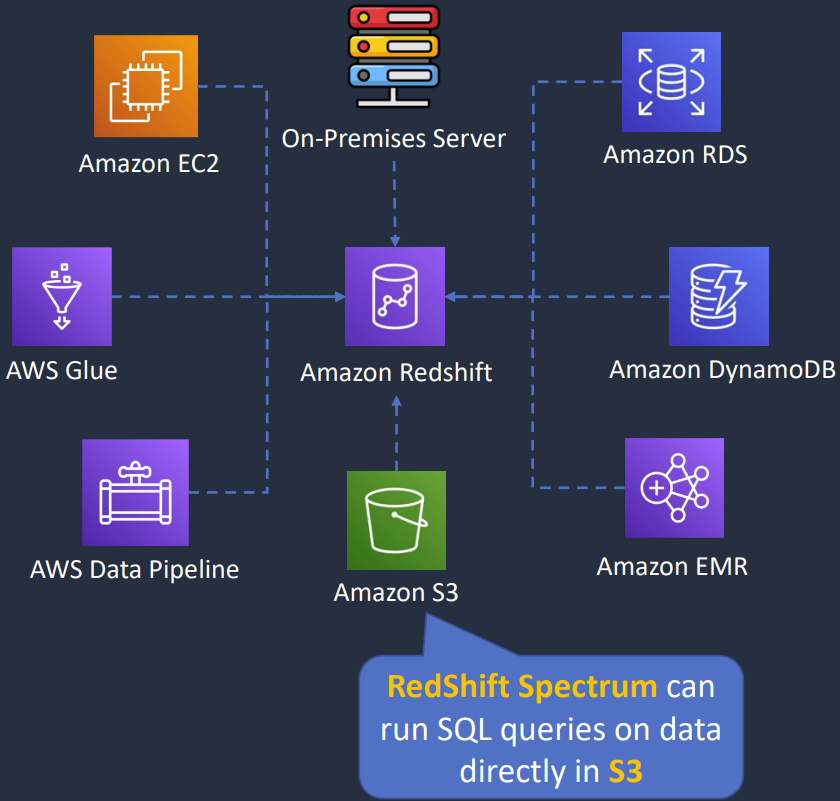
Redshift and OLAP Use Cases
Use Cases
- Sử dụng khi cần query phức tạp trên 1 bộ data lớn (có cấu trúc hoặc không) và cần performance nhanh
- Dữ liệu được truy cập thường xuyên cần có định dạng nhất quán, có cấu trúc cao
- Sử dụng Spectrum để truy cập trực tiếp S3 object trong datalake
- Data warehouse solution được quản lý với các tính năng
- Tự động khởi tạo, config, vá lỗi
- Độ bền dữ liệu với sao lưu liên tục vào S3
- Thay đổi quy mô bằng cách gọi API
- Exabyte scale query (= 1000 PB = 1000.000 TB)
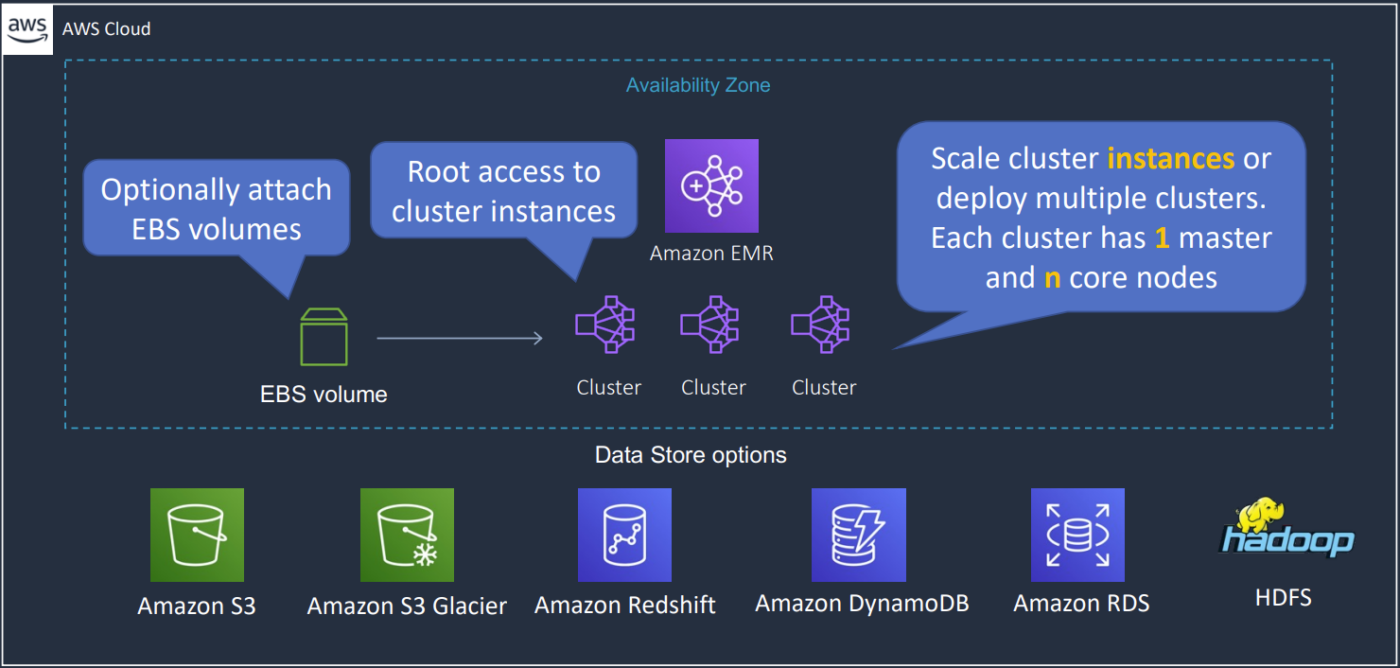
Amazon EMR
Big data framework, bao gồm Apache Hadoop và Apache Spark, được sử dụng để xử lý data để phân tích, cũng có thể dùng để chuyển đổi và di chuyển một lượng lớn dữ liệu, và thực hiện ETL function.
EMR Integrations
- Amazon EC2 – the instances that comprise the nodes in the cluster
- Amazon VPC – configure the virtual network in which you launch your instances
- Amazon S3 – store input and output data
- Amazon CloudWatch – monitor cluster performance and configure alarms
- AWS IAM – configure permissions
- AWS CloudTrail – audit requests made to the service
- AWS Data Pipeline – schedule and start your clusters
- AWS Lake Formation – discover, catalog, and secure data in an Amazon S3 data lake
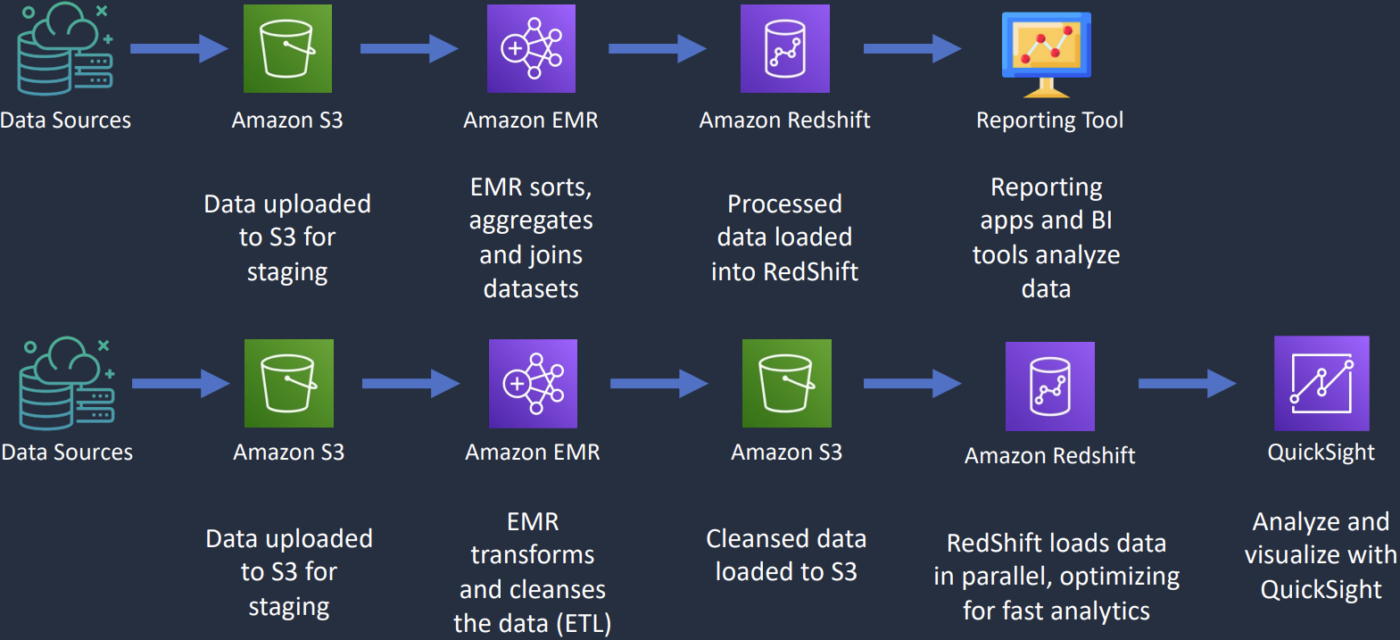
Amazon Timestream
- Time seri database service cho IoT và application operational
- Nhanh và rẻ hơn so với RDS
- Lưu data gần đây trong memory và move history tới storage tier có cost optimized dựa theo policy user define
- Serverless, scale automatic
Amazon QuickSight
- Serverless, ML service tạo ra các dashboard
- Tự động scale
- Use case
- Business analytics
- Building visualizations
- Perform ad-hoc analysis
- Get business insights using data
- Tích hợp cùng RDS, Aurora, Athena, Redshift, S3…
AWS Data Exchange
- Là Marketplace với 3000+ sản phẩm và 250+ nhà sản xuất
- Hỗ trợ Data Files, Data Tables, Data APIs
- Consume trực tiếp tới data lake, application, analytic, machine learning model
- Automatic export data set mới/được update tới S3
- Query data table với AWS Data exchange cho Amazon Redshift
- Sử dụng AWS-native authentication và governance, AWS SDKs, và API Document
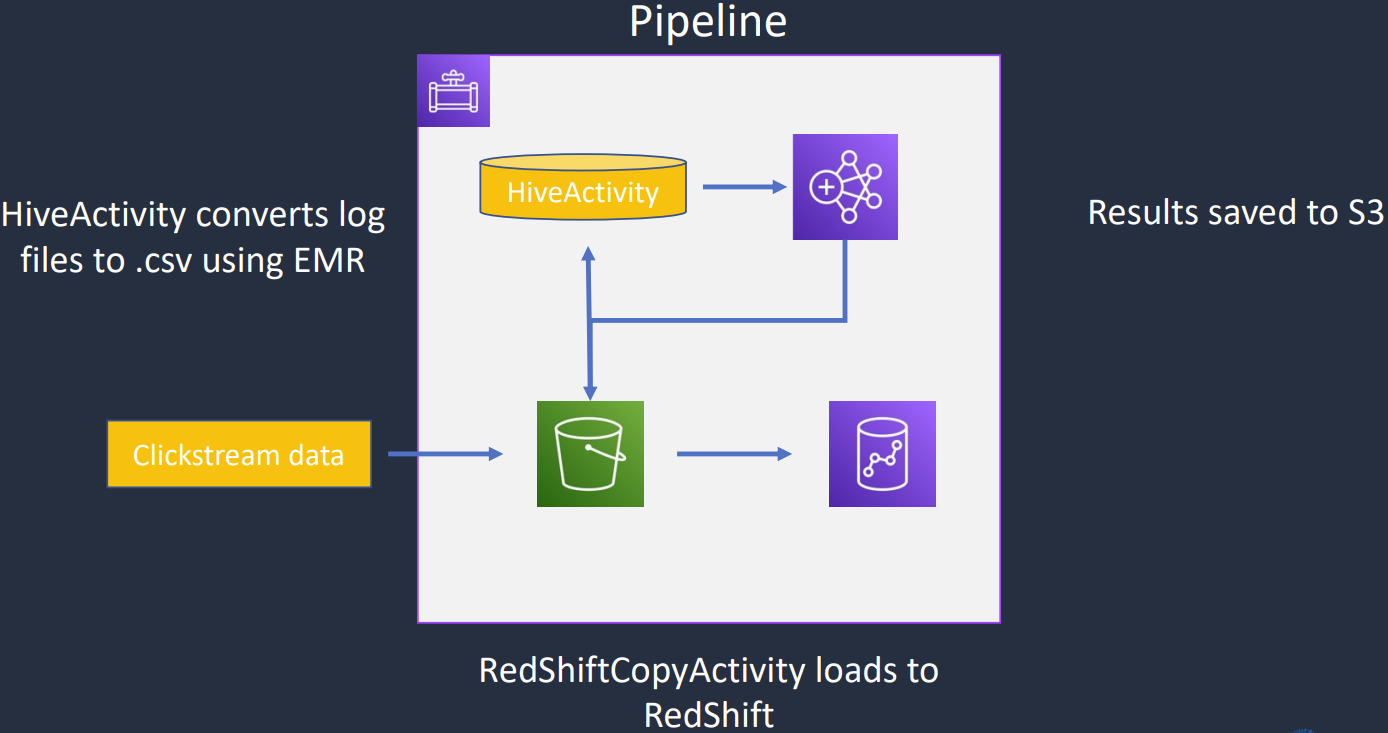
AWS Data Pipeline
- Là ETL Service
- Process và move data giữa các AWS compute và Storage Service
- Data source có thể từ On-Premises
- Data có thể process và transform
- Destination có thể là S3, RDS, DynamoDB, Amazon EMR
AWS Lake Formation
- AWS Lake Formation cho phép bạn thiết lập data lake an toàn trong vài ngày, thường thì sẽ lâu hơn, tính bằng tuần hoặc tháng.
- Dữ liệu có thể được thu thập từ database và object storage, sau đó lưu trữ trong data lake Amazon S3.
- Có thể clean và phân loại dữ liệu bằng các thuật toán học máy (ML).
- Security có thể được áp dụng ở cấp cột, dòng và ô.
- Data set sau đó có thể được sử dụng thông qua các dịch vụ như Amazon Redshift, Amazon Athena, Amazon EMR for Apache Spark và Amazon QuickSight.
- Lake Formation xây dựng trên các khả năng có sẵn trong AWS Glue. (Lake Formation builds on the capabilities available in AWS Glue)
Amazon Managed Streaming for Apache Kafka (MSK)
- Thu thập và xử lý dữ liệu streaming trong thời gian thực, khác với Kinesis do AWS cung cấp còn Kafka là mã nguồn mở
- Cluster và Serverless
- Nó cung cấp cấu hình, triển khai và duy trì các cluster Apache Kafka và các node Apache ZooKeeper.
- Data lưu trong EBS
- Consumer đa dạng
- Kinesiss Data Analytic
- Glue
- Lambda
- Tự cài Consumer
- Các cấp độ bảo mật bao gồm:
- VPC
- AWS IAM để kiểm soát quyền truy cập vào API điều khiển
- Encryption tại nơi lưu trữ (at rest)
- Mã hóa TLS trong quá trình truyền tải (in-transist)
- Xác thực chứng chỉ dựa trên TLS
- Xác thực SASL/SCRAM được bảo vệ bởi AWS Secrets Manager.
